
Informationen entlang der Wertschöpfungskette effizient zu verwalten, um dadurch Geschäftsprozesse gezielt steuern zu können, gehört heutzutage zu den entscheidenden Fähigkeiten im Unternehmen. Der Digitalisierung kommt hierbei eine Schlüsselrolle zu, da sie die notwendigen Grundlagen schafft, um ein durchgängiges Informationsmodell zu entwickeln, das der manuellen Datenpflege und dem fragmentierten Datenaustausch ein Ende setzt.
Digitale Transformation gilt als ressourcen- und zeitaufwändig, weshalb viele Unternehmen davor zurückschrecken, einen derart großen Schritt zu unternehmen. Dabei wird häufig übersehen, dass ein zentrales Informationsmanagement und ein nahtloser, automatisierter Informationsaustausch einen großen Wettbewerbsvorteil darstellen sowie Skalierbarkeit von Geschäftsprozessen deutlich erhöht.
Unternehmen, die es heutzutage nicht schaffen, im Rahmen ihrer Digitalisierung eine einheitliche, zentralisierte Datenquellen für ihre Produktarchitekturen (Baukasten) aufzubauen, müssen mit unnötiger Mehrarbeit und Fehlern bei der Datenübertragung und -pflege rechnen und längere Entwicklungs- und Durchlaufzeiten bei erhöhten Kosten in Kauf nehmen.
Um digitale Transformation im Unternehmen zu ermöglichen, ist es jedoch notwendig, zuerst den aktuellen Status Quo des Informationsmanagements für die Produktarchitekturen und die verschiedenen am Datenaustausch beteiligten Geschäftsprozesse genau zu analysieren. Wie das funktioniert, zeigen wir Ihnen in diesem Blog-Artikel.
Dazu werden wir zunächst erklären, was eine gute Produktarchitektur ausmacht und welche Daten für ein zentrales Informationsmodell für Produktarchitekturen relevant sind. In einem weiteren Schritt werden wir die Vorteile eines einheitlichen Informationsmodells erörtern und aufzeigen, wie Unternehmen ihr aktuelles Datenmanagement und ihre Prozesse analysieren müssen, um eine solide Grundlage für den Aufbau eines effizienten und durchgängigem Datenmanagements zu schaffen.

Was macht eine gute Produktarchitektur aus?
Die Produktarchitektur beschreibt, wie Produkte aufgebaut sind. Sie gibt an, wie ein Produktsortiment strukturiert ist und gegebenenfalls wie groß eine gemeinsam genutzte Plattform ist. Eine Produktarchitektur so aufzubauen, dass die unterschiedlichen Produkte eine gemeinsame Basis haben, ermöglicht es, technische Lösungen, Software, Strukturen und Teile gemeinsam zu nutzen.
Das schafft nicht nur Vorteile für die F&E-Abteilung oder Konstruktion, sondern auch für andere Funktionen wie Einkauf, Produktion, Vertrieb, Marketing und Produktplanung. Eine gut strukturierte Produktarchitektur kommt folglich allen Teilen des Unternehmens zugute, da sie Effizienz, Flexibilität und Agilität ermöglicht. Ein wichtiges Schlüsselkonzept hierfür ist die Modularisierung.
Mithilfe der Modularisierung lassen sich Produkte und Produktarchitekturen in einem System von austauschbaren Funktionsbausteinen organisieren, auf dessen Basis sich problemlos unterschiedliche Produktvarianten ausprägen lassen. Die einzelnen Funktionsbausteine werden Module genannt. Von ihnen sind im modularen Baukastensystem verschiedene Varianten angelegt, die sich unter Berücksichtigung vorgegebener Kombinationsregeln zu verschiedenen Produktvarianten zusammensetzen lassen.
Jedes Modul erfüllt dabei klar abgegrenzte Funktionen und verfügt über standardisierte Schnittstellen, die eine hohe Wiederverwendbarkeit innerhalb des modularen Systems gewährleisten. Wenn verschiedene Bauteile in mehreren Produktvarianten verwendet werden können, kann das Unternehmen Skaleneffekte bei der Produktion der Module erreichen und seinen Kunden gleichzeitig ein vielfältiges Produktportfolio anbieten. Eine gute Produktarchitektur ist also im besten Fall modular.
Leseempfehlung: Für einen tieferen Einblick in das Thema Modularisierung und alle damit in Verbindung stehenden Konzepte lesen Sie unseren Blog-Artikel “Alles, was Sie zu Modularisierung wissen müssen”.
Welche Daten gehören in ein Informationsmodell für Produktarchitekturen?
Bei der Entwicklung einer Produktarchitektur müssen geeignete Datenmengen gesammelt, systematisiert und gespeichert werden. Zu diesen Daten gehören:
- Kundendaten
- Informationen über verschiedenen Marktsegmente und Kundenbedürfnisse
- Technische Spezifikationen
- Konstruktionsunterlagen
- Informationen zu Preisgestaltung und Funktionsumfang
- Informationen zu den Kosten einzelner Teile und Produkte
- Informationen zu Verfügbarkeit und Vorlaufzeiten
Einteilen lassen sich die Daten grundsätzlich in Daten, die in direktem Zusammenhang mit der Dokumentation der Produktarchitektur stehen, und zusätzliche Metadaten, die weiterführende Informationen bereitstellen, die einen reibungslosen Ablauf und eine effektive Steuerung der internen Prozesse ermöglichen.
Die Daten, die konkret zur Dokumentation der Produktarchitektur benötigt werden, umfassen:
- Informationen zu Modulen und Modulvarianten
- Informationen zu Schnittstellen und Kombinierbarkeit verschiedener Module
- Informationen zur generischen Produktstruktur, in die sich verschiedene Modulvarianten einsetzen lassen, um neue Produktvarianten zu erzeugen
Die gesammelten Informationen zu Modulen, Modulvarianten, Schnittstellen, Produktstruktur und Konfigurationsregeln bilden die Minimalanforderung zur Dokumentation einer Produktarchitektur. Es können jedoch zahlreiche Metadaten hinzugefügt werden, um verschiedene Aspekte der Architektur zu dokumentieren, wie z. B. Informationen zu Kundenbedürfnissen, Produktleistung, Marktstrategien, Produktfamilien, prognostizierte Absatzmengen und mehr. Kurz gesagt: Daten, die die Entscheidungsfindung über die gesamte Lebensdauer der Produktarchitektur hinweg unterstützen, damit diese konstant weiterentwickelt und gepflegt werden kann.
Datenmanagement auf Dokumentenebene vs. zentrales Informationsmodell
In vielen Unternehmen stellt sich jedoch das Problem, dass all diese Informationen zwar vorhanden, aber weitgehend unstrukturiert und über verschiedene Systeme und Dokumente hinweg verstreut sind - beziehungsweise auch im Erfahrungsschatz und dem Wissen einiger langjähriger Mitarbeiter liegen. In solchen Fällen sprechen wir von einer Datenspeicherung auf Dokumentenebene, in der wichtige Informationen in verschiedene Silos unterteilt sind. Das Gegenmodell hierzu bildet ein zentrales Informationsmodell, das alle Informationen bezüglich der Produktarchitektur sowie weitere wichtige Metadaten in einem zentralen System bündelt. Schauen wir uns beide Ansätze im Detail an, um zu sehen, welche Vor- und Nachteile sich jeweils für das Unternehmen ergeben.
Datenmanagement im Unternehmen auf Dokumentenebene
Verwaltet ein Unternehmen seine Daten auf Dokumentenebene, ist ein manueller Informationsaustausch zwischen und sogar innerhalb von einzelnen Unternehmensabteilungen erforderlich. Dabei werden Informationen und Datensätze unstrukturiert in verschiedenen Formaten wie Dokumenten, Tabellenkalkulationen und Präsentationen gespeichert. Klare Regeln, wo welche Informationen gespeichert werden, wie sie nach Versionen kategorisiert werden und wie der Zugriff kontrolliert wird, gibt es in der Regel nicht. Das Resultat ist ein hoher Aufwand für die manuelle Datenverwaltung und -pflege, die darüber hinaus häufig zu Fehlern und Dateninkonsistenz führt. Die Qualität der Daten nimmt ab und es kommt zu Mehrarbeit, da gleiche Datensätze an mehreren Stellen gepflegt werden müssen, was häufig zu Diskrepanzen in den Datensätzen führt.
Innerhalb einer einzelnen Abteilung mag ein auf Dokumentenebene durchgeführtes Informationsmanagement noch funktionieren, geht es jedoch an den Informationsaustausch mit anderen Abteilungen, kommt der Ansatz schnell an seine Grenzen. Die nachfolgende Grafik verdeutlicht den schleppenden und wenig transparenten Informationsfluss zwischen verschiedenen Unternehmensfunktionen, wenn der Informationsaustausch durch das manuelle Weiterleiten und Teilen von Dokumenten erfolgt.
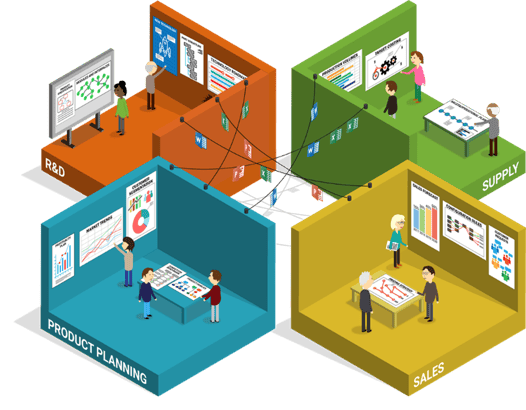
Datenmanagement im Unternehmen mit einem zentralen Informationsmodell
Eines der Hauptziele von Digitalisierung im Unternehmen besteht darin, die häufig bestehende Trennung zwischen den Systemen verschiedener Unternehmensfunktionen aufzuheben und die unterschiedlichen IT-Lösungen innerhalb der Organisation miteinander zu verbinden. Genau das wird durch ein zentrales Informationsmodell möglich.
Ein zentrales Informationsmodell ermöglicht es, die verschiedenen Unternehmensfunktionen auf Datenebene miteinander zu verbinden. Daten und Informationen werden zentralisiert in einer für alle Unternehmensbereiche zugänglichen Datenbank gespeichert und der Datenaustausch erfolgt nahtlos von Abteilung zu Abteilung (s. Grafik). Strukturierung, Versionierung und Zugriff auf die Datensätze werden zentral gesteuert und die Systeme der verschiedenen Abteilungen wie CPQ, PD/PLM und ERP nutzen dieselben Stammdaten über automatisierte Integrationen.
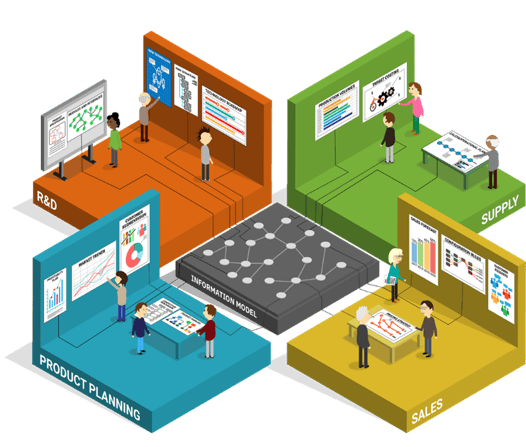
Der Wandel hin zum vernetzten Unternehmen mit einem nahtlosen Informationsaustausch ist jedoch mit Aufwänden verbunden. Nicht selten kommt es im Laufe solcher Integrationsprojekte zu Verzögerungen, die die Projektkosten in die Höhe treiben und im schlimmsten Fall zum Scheitern des Projekts führen können. Die Gründe dafür können technischer Natur sein, oder aber es liegt daran, dass ein abteilungsübergreifendes Datenformat sowie adäquate Regeln für den Datenaustausch zwischen den verschiedenen Systemen fehlen.
Jedes Informationssystem im Unternehmen strukturiert und verwaltet die benötigten Datensätze auf eine andere Art und Weise, weswegen es schwierig ist, das jeweilige Datenformat von einem System ins nächste zu übertragen. Man kann sich dieses Problem so vorstellen, als würde man versuchen, einen komplexen Sachverhalt zu verstehen, obwohl man eine andere Sprache spricht als die, in der der Sachverhalt erklärt und dokumentiert ist. Daher ist es von entscheidender Bedeutung, eine gemeinsame Sprache zu entwickeln, die von allen Systemen im Unternehmen gleichermaßen verstanden wird.
Diese Sprache ist das zentrale Informationsmodell für die Produktarchitektur des Unternehmens, welches für den Austausch über verschiedene Geschäftsprozesse und Unternehmensfunktionen hinweg benötigt wird. Das Modell wird mit Daten angereichert, die zur Steuerung eines bestimmten Prozesses innerhalb der Organisation erforderlich sind, sodass vor- und nachgelagerte Prozesse auf diese Daten zugreifen und sie ihrerseits verwenden können. Das schafft einen durchgängigen digitalen roten Faden, der sich durch alle Abteilungen des Unternehmens zieht (s. Grafik).
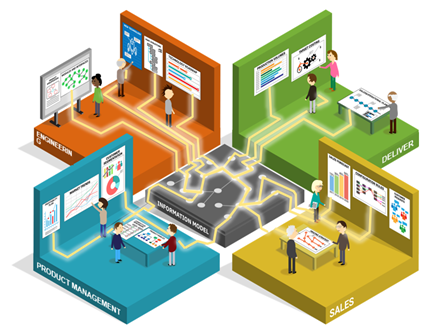
Leseempfehlung: Modularität und Konfigurierbarkeit sind die beiden Grundbausteine für eine gute Produktarchitektur. Wie diese beiden Grundbausteine konkret in einem Informationsmodell realisiert werden können, lesen Sie in unserem Blog-Artikel “Das passende Informationsmodell für Produktkonfiguration”.
Analyse des Status Quo als Grundlage für ein zentrales Informationsmodell
Erfolgreiche digitale Transformation bietet Unternehmen viele verschiedene Vorteile. Zum einen sorgt ein zentrales Informationsmodell für weniger Arbeitsaufwand in Datenmanagement und -pflege, was wiederum Kapazitäten für andere Projekte und Aufgaben schafft. Zum anderen erhöht sich die Datenqualität, da Datensätze abteilungsübergreifend aktualisiert und gepflegt werden, sodass es nicht mehr zu Fehlern in wichtigen Datensätzen kommt. Da Daten schneller und vollständiger zwischen den Abteilungen ausgetauscht werden können, verkürzen sich außerdem die Vorlauf- und Durchlaufzeiten.
Um die Grundlage für ein einheitliches Informationsmodell zu legen, müssen Unternehmen jedoch zuerst die bestehenden Probleme und Herausforderungen in ihrem Informationsmanagement analysieren. Nur so kann ermittelt werden, welche Maßnahmen ergriffen werden müssen, um eine nachhaltige Verbesserung zu erreichen. Im Rahmen dieser Erfassung des Status Quo sollten außerdem Potentiale zur Kostenersparnis quantifiziert werden. So kann die Unterstützung durch die Unternehmensführung gesichert werden. Diese ist bei einem umfangreichen Transformationsprojekt unerlässlich.
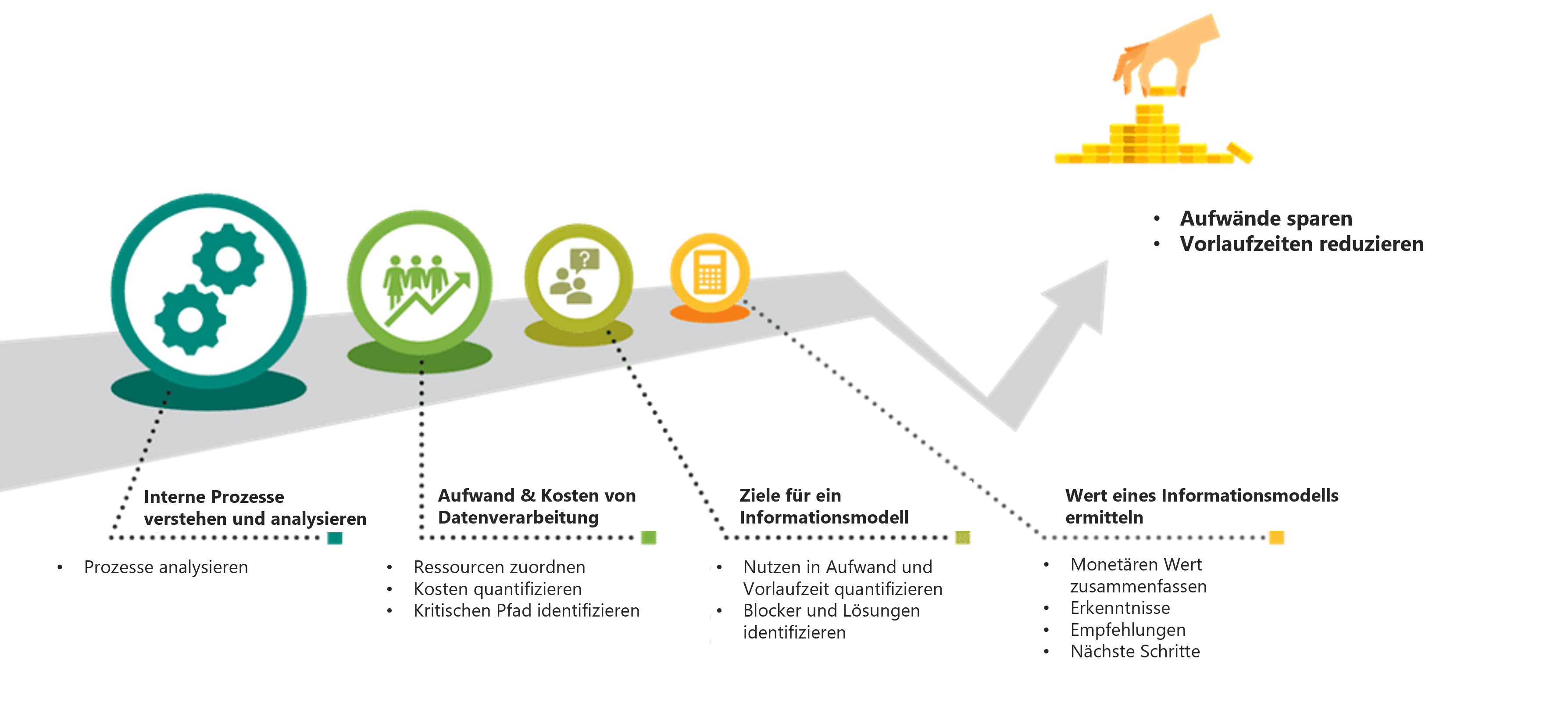
Zur Analyse des Ist-Zustandes der Informationsverwaltung können sich Unternehmen an den folgenden vier Schritten orientieren.
Schritt 1: Interne Prozesse verstehen und analysieren
In einem ersten Schritt geht es darum, sich einen Überblick darüber zu verschaffen, welche Unternehmensfunktionen auf welche Datensätze zugreifen. Dazu müssen alle Prozesse im Unternehmen analysiert werden, die an die Verwendung von Daten geknüpft sind. Stützen können sich Unternehmen hierbei auf verfügbare Prozessdokumentationen. Bei fehlender Prozessdokumentation müssen die Lücken geschlossen werden, hierfür können generische Prozesspläne genutzt werden, die an die spezifischen Arbeitsabläufe im Unternehmen angepasst werden. Anschließend sollten die Ergebnisse der Geschäftsprozessanalyse von den jeweiligen Prozessverantwortlichen validiert werden.
Schritt 2: Aufwand und Kosten von Datenverarbeitung ermitteln
In einem nächsten Schritt werden die Personalkosten erfasst, die für die Verarbeitung von Daten in Prozessen anfallen. Diese Analyse kann in der Regel zusammen mit Controlling und den Prozessverantwortlichen durchgeführt werden. Ermittelt wird hierbei der jeweilige Ressourcenaufwand der verschiedenen Prozesse und Prozessschritte. Auch wird festgelegt, welche Schritte unbedingt notwendig sind, um den Prozess erfolgreich abzuschließen.
Schritt 3: Ziele für ein Informationsmodell mit den Prozessverantwortlichen ermitteln
In diesem Schritt geht es darum, die Frage zu beantworten, wie ein nahtloser automatischer Informationsaustausch, den manuellen Aufwand in den einzelnen Prozessschritt reduzieren könnte. Auch die Verringerung der Vorlaufzeit für jeden Prozessschritt sollte hierbei in Betracht gezogen werden, ebenso wie potenzielle Hindernisse, die einer Prozessautomatisierung im Weg stehen, und Lösungen, diese zu umgehen.
Schritt 4: Wert eines zentralen Informationsmodells ermitteln
Eine gemeinsame Betrachtung der Basiskosten für die Ausführung der einzelnen Prozesse und der Aufwandsersparnis pro Prozessschritt ermöglicht es, den Wert eines zentralen Informationsmodells für das Unternehmen genau zu beziffern. Mithilfe der Berechnung lassen sich auch Ineffizienzen in der Prozessausführung aufdecken, die auf unzureichende Informationen zurückzuführen sind.
Die einzelnen Schritte haben wir für Sie noch einmal in der nachfolgenden Grafik zusammengefasst.
Wie bei jeder funktionsübergreifenden Geschäftsprozessanalyse ist es wichtig, dass die Analyse einen Rahmen erhält und die Unterstützung aller Stakeholder hat. Vor Beginn sollte daher der Umfang der Analyse mit dem Managementteam abgestimmt werden. In anderen Worten: Welche Unternehmensfunktionen und Prozesse sollen analysiert werden und welche nicht? Welche Einschränkungen gibt es und welche Ergebnisse werden erwartet?
Um die Unterstützung der Führungskräfte in allen Unternehmensfunktionen zu gewinnen, ist es wichtig:
● Alle Abteilungsleiter innerhalb des Untersuchungsbereiches miteinzubeziehen und das Vorgehen genau zu erläutern
● Einen internen Projektleiter für die Analyse zu ernennen
● Einen Projektplan mit konkreten Zielsetzungen und Kontrollpunkten zu erstellen
Mit einem einheitlichen Informationsmodell Mehrwert im Unternehmen schaffen
In vielen Unternehmen ist das Informationsmanagement fragmentiert und nicht abteilungsübergreifend gelöst. Viele Unternehmensfunktionen müssen für das Ausführen verschiedener Geschäftsprozesse auf die gleichen Datensätze zugreifen, aber der Datenaustausch ist nicht standardisiert, was Prozesse verlangsamt. Aufgrund einer fehlenden zentralisierten Datenbasis kommt es außerdem zu Mehraufwand bei der Datenpflege, was dazu führen kann, dass verschiedene Abteilungen mit unterschiedlichen Versionen der Datensätze arbeiten.
Das Ziel digitaler Transformation im Unternehmen besteht darin, solche Diskrepanzen im Datenmanagement zu vermeiden und ein einheitliches Informationsmodell zu schaffen, das nicht nur die grundlegenden Daten enthält, die die Produktarchitektur beschreiben, sondern darüber hinaus auch eine Reihe von Metadaten liefert, die das Informationsmodell vervollständigen.
Ein solches Informationsmodell zu erstellen ist zeit- und kostenaufwendig, bietet Unternehmen jedoch viele Vorteile, darunter ein weniger ressourcenintensives Datenmanagement und verkürzte Vorlauf- und Durchlaufzeiten als auch Fehlerminimierung und damit verbundene Kosten. Um den Erfolg des Transformationsprojekts zu gewährleisten, müssen Unternehmen als Grundlage eine detaillierte Geschäftsprozessanalyse durchführen, die ihnen dabei hilft, genau zu verstehen, welche Prozesse auf welche Daten zugreifen. Auch eine gut strukturierte Produktarchitektur, die sich aus klar definierten Modulen und Konfigurationsregeln zusammensetzt, erleichtert das Konsolidieren der verschiedenen Datensätze.
Das große Ziel, das mit vereinheitlichen und digitalisierten Information angestrebt wird, ist eine nahtlose end-to-end Konfiguration von Produkten, bei der nach der Konfiguration eines Produktes durch den Kunden nahezu automatisch Fertigungsunterlagen erstellt und der Produktionsprozess angestoßen wird. Hierbei ist zu beachten, dass die Produktkonfiguration zu Produkt, Entwicklungs- und Verkaufsprozessen passen muss. Mit unserem Product Configuration Navigator können Sie prüfen, ob Sie die optimale Implementierung von Produktkonfiguration für Ihren Unternehmens- und Produktkontext nutzen.

 AUTHOR
AUTHOR
Johan Källgren
Executive Vice President
+46 8 456 35 00
johan.kallgren@modularmanagement.com
Weitere Ressourcen
Eine Einführung, basierend auf der Erfahrung von Führungskräften aus erster Hand, in die Vernetzung eines Unternehmens durch architekturgestützte Digitalisierung.
Ein Leitfaden zur Abbildung von Geschäftsprozessen. Die Abbildung von Prozessen ist ein umfangreiches Thema mit einer endlosen Anzahl von Leitfäden und Ansätzen. Suchen Sie nach Quellen, die für Ihre Anforderungen relevant sind, und verwenden Sie Methoden, die in Ihrer Organisation bereits vorhanden sind.